



























Thời gian gần đây, những tác phẩm nghệ thuật do công nghệ trí tuệ nhân tạo (AI) tạo ra trở nên bùng nổ kể từ khi OpenAI* phát hành các mã nguồn cho mô hình CLIP của họ. Nhiều hacker, nghệ sĩ, nhà nghiên cứu,… đã sử dụng CLIP như một “tay lái ngôn ngữ tự nhiên”.
*OpenAI: công ty nghiên cứu và triển khai công nghệ AI – mang trí tuệ nhân tạo hữu ích trên nhiều lĩnh vực.
CLIP hiệu quả cho các mô hình khác nhau, cho phép các nghệ sĩ sáng tạo nghệ thuật thị giác chỉ bằng cách nhập văn bản, chú thích, bài thơ, lời bài hát, hoặc thậm chí là một từ vào trong những mô hình này.

Tác phẩm vui nhộn khi nhập “một bức tranh trừu tượng về một hành tinh được cai trị bởi những lâu đài nhỏ”
Tất cả những gì bạn cần là nhập một số ý tưởng của mình dưới dạng chữ, hệ thống sẽ hiển thị chúng theo phong cách trừu tượng hoặc theo một phong cách riêng nào đó. Những mô hình này sáng tạo linh hoạt đến mức bạn sẽ ngạc nhiên vì không thể biết được kết quả xảy ra như thế nào. Kết quả tạo ra có thể là cảnh siêu thực, phong cách trừu tượng hoặc tối giản. Và bạn có thể tạo ra hầu hết mọi thứ.
Hai phương pháp tiêu biểu để tạo nên những mô hình nghệ thuật của OpenAI là Dall-E và CLIP. Dall-E tạo ra các hình ảnh chất lượng cao trực tiếp từ ngôn ngữ, trong khi phương pháp CLIP giống như một thủ thuật sử dụng ngôn ngữ để điều khiển các mô hình tạo hình ảnh vô điều kiện.
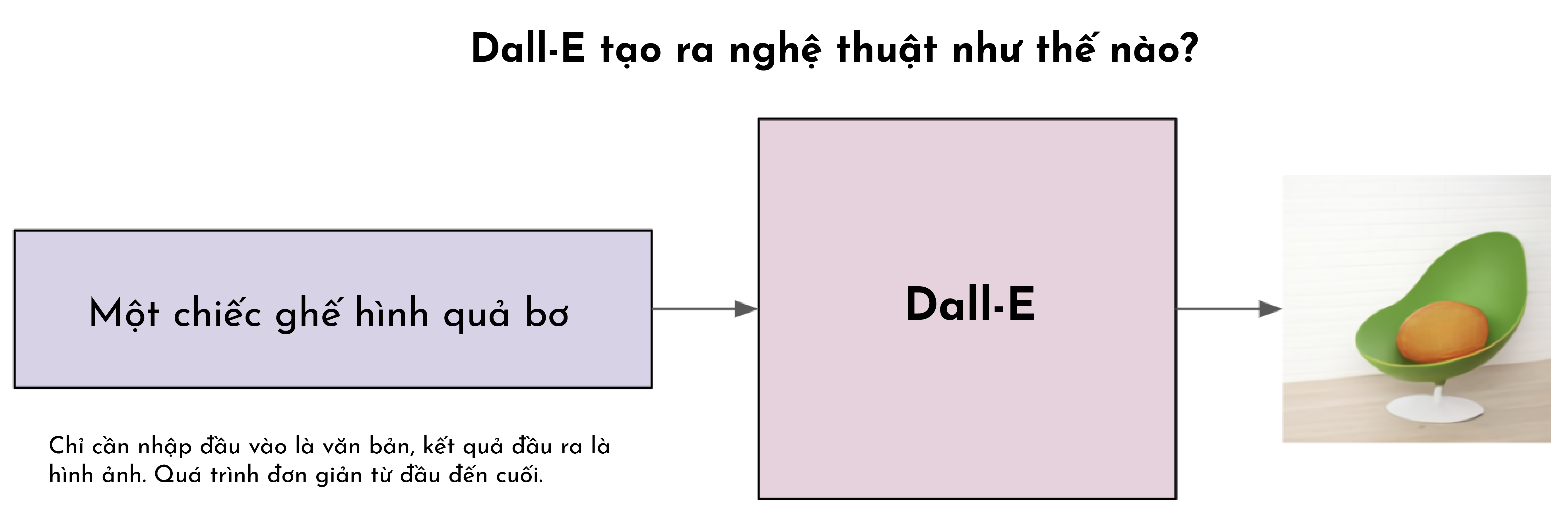
Quá trình tạo văn bản thành hình ảnh của DALL-E.
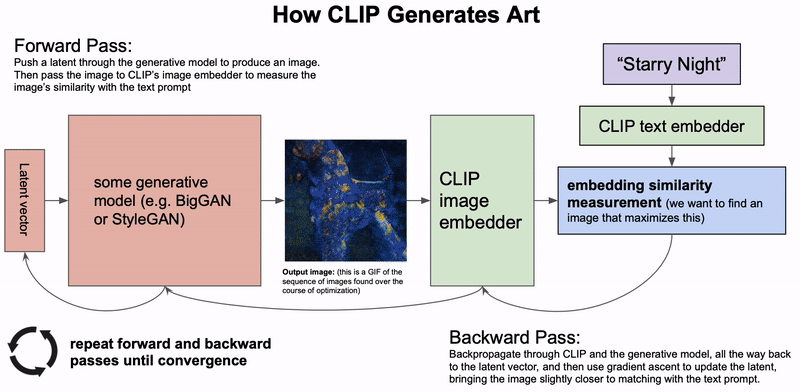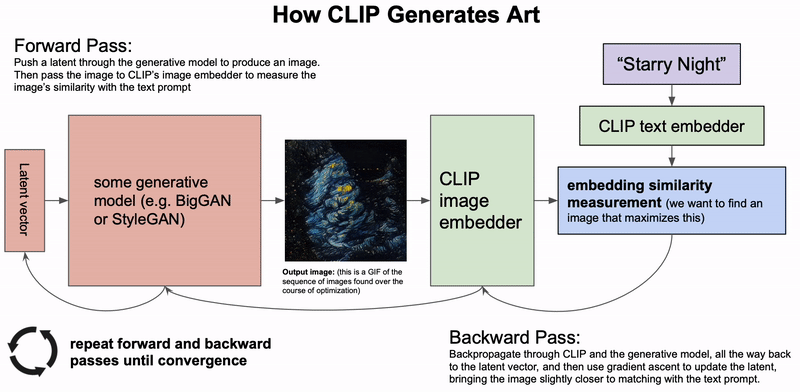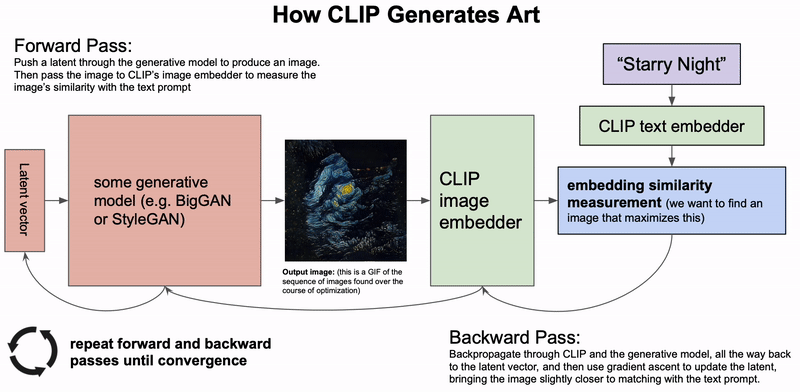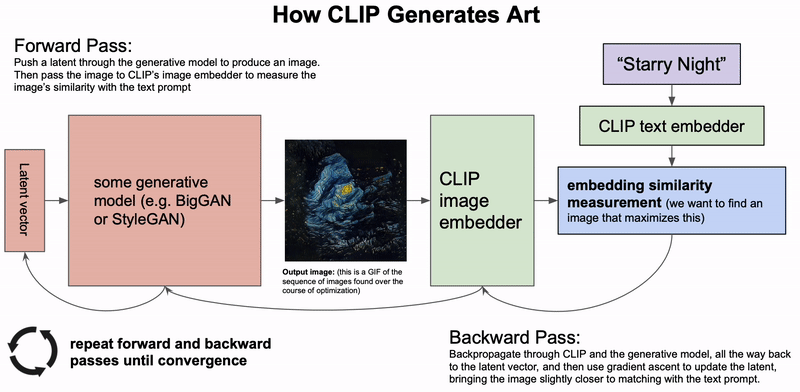
Quá trình CLIP tạo ra tác phẩm nghệ thuật
So với Dall-E, cách tiếp cận của hệ thống CLIP hơi khó hiểu hơn. Kết quả đầu ra của CLIP có thể không được chất lượng cao và chính xác như Dall-E. Nhưng những hình ảnh được tạo ra bởi CLIP rất lạ, trừu tượng và mang hơi hướng phá cách. Kết quả đầu ra này như những hình ảnh trong thế giới của chúng ta, nhưng giống như được tạo ra bởi một người ngoài hành tinh với góc nhìn khác biệt.
Chính sự kỳ lạ đã làm cho các tác phẩm tạo bởi CLIP trở nên đẹp mắt và nghệ thuật. Góc nhìn mới về những thứ quen thuộc làm cho những tác phẩm này đặc biệt.

Kết quả của Dall-E và CLIP cho chiếc ghế hình quả bơ
Gần đây, mạng xã hội Twitter tràn đầy hình ảnh nghệ thuật tạo bởi CLIP. Cộng đồng này đang tăng số lượng thành viên rất nhanh, bao gồm các nghệ sĩ, nhà nghiên cứu và cả hacker đã và đang thử nghiệm các mô hình này và chia sẻ kết quả đầu ra của họ. Mọi người cũng chia sẻ mã và các thủ thuật khác nhau để sửa đổi chất lượng hoặc phong cách nghệ thuật của hình ảnh được tạo ra. Phong trào này như tạo nên một trường phái nghệ thuật mới nổi.
CLIP: Câu chuyện nguồn gốc bất ngờ
Ngày 05/01/2021, OpenAI phát hành trọng số mô hình và mã code cho CLIP. Một mô hình được tạo ra để nhận định mô tả nào phù hợp với một hình ảnh nào. Sau khi học từ hàng trăm triệu hình ảnh theo cách này, CLIP không chỉ trở nên khá thành thạo trong việc chọn ra mô tả tốt nhất cho một hình ảnh nhất định, mà nó còn học được một số đại diện tổng quát và trừu tượng đáng ngạc nhiên.
Ví dụ, CLIP đã học cách đại diện cho nơ-ron kích hoạt đặc biệt cho các hình ảnh và khái niệm liên quan đến Người Nhện. Ngoài ra còn có các nơ-ron khác kích hoạt hình ảnh liên quan đến cảm xúc, vị trí địa lý hoặc thậm chí các cá nhân nổi tiếng.
Vì vậy, từ góc độ nghiên cứu, CLIP là một mô hình cực kỳ thú vị và có sức sống. Nhưng cũng không có gì cho thấy rõ nó sẽ hữu ích trong việc tạo ra nghệ thuật. Tuy vậy, các nhà nghiên cứu và các nghệ sĩ phát hiện ra rằng với một thủ thuật đơn giản, CLIP thực sự có thể được sử dụng để hướng dẫn các mô hình tạo hình ảnh hiện có (như GAN, Autoencoders) để tạo hình ảnh gốc phù hợp với mô tả nhất định.
Trong phương pháp này, CLIP hoạt động giống như một “tay lái ngôn ngữ tự nhiên” cho các mô hình chung. CLIP hướng dẫn tìm kiếm thông qua không gian tiềm ẩn của một mô hình tổng quát để tìm ra mối liên quan đến hình ảnh phù hợp với một chuỗi từ nhất định.
Kết quả ban đầu bằng cách sử dụng kỹ thuật này rất kỳ lạ nhưng vẫn đáng ngạc nhiên và đầy hứa hẹn:

Nguồn: @quasimondo trên Twitter
The Big Sleep: Khởi đầu khiêm tốn
The Big Sleep được phát hành, trở thành kỹ thuật đột phá chuyển văn bản thành hình ảnh dựa trên CLIP, sử dụng Big GAN làm mô hình chung.
The Big Sleep chuyển văn bản thành hình ảnh theo cách độc đáo của riêng mình. Nó có thể hiển thị bất cứ thứ gì bạn có thể diễn đạt thành từ như “hoàng hôn”, “khuôn mặt giống như bức vẽ MC Escher”, “khi gió thổi”, “hẻm núi lớn ở dạng 3D”.
Kết quả đầu ra từ The Big Sleep không dự đoán được trước. Chúng kỳ lạ, trừu tượng và đôi khi chúng không có nhiều ý nghĩa. Các tác phẩm nghệ thuật do The Big Sleep tạo ra đều có một phong cách riêng và nhiều cá nhân đánh giá nó rất đẹp mắt về mặt thẩm mỹ.

Hình ảnh “Khi gió thổi” from The Big Sleep (Nguồn: @advadnoun trên Twitter)
Nhưng điều kỳ diệu và mê hoặc của The Big Sleep không thật sự đến từ tính thẩm mỹ của nó, mà do chúng phù hợp với mô tả. Mục tiêu tối ưu của The Big Sleep khi tạo hình ảnh là tìm một điểm trong không gian tiềm ẩn GAN tương ứng tối đa với một chuỗi từ nhất định trong CLIP. Vì vậy, khi nhìn vào kết quả đầu ra từ The Big Sleep, chúng ta thực sự đang thấy cách CLIP diễn giải các từ và cách mô hình “nghĩ” chúng tương ứng với thế giới hình ảnh của chúng ta.
CLIP giống như bộ não người ngoài hành tinh mà chúng ta có thể mở khóa và nhìn vào với sự trợ giúp của The Big Sleep. CLIP không thực sự quá thông minh, nhưng nó vẫn cho chúng ta thấy một cái nhìn thú vị về mọi thứ.
Bạn có thể nghĩ kết quả đầu ra của CLIP là sản phẩm của các số liệu thống kê đơn thuần: kết quả của việc tính toán các mối tương quan giữa ngôn ngữ và thị giác khi chúng tồn tại trên internet. Và do đó, với quan điểm này, kết quả đầu ra từ CLIP giống như một “thống kê trung bình của internet”.

Kết quả hình ảnh từ nội dung đầu vào: “Kết thúc của mọi thứ, tòa nhà đổ nát và vũ khí chọc thủng bầu trời” từ The Big Sleep (Nguồn: @advadnoun trên Twitter)
“The grand canyon in 3d” theo The Big Sleep
The Big Sleep không phải là kỹ thuật nghệ thuật AI đầu tiên ghi lại cảm giác kỳ diệu khi nhìn vào “tâm trí” mạng nơ-ron nhân tạo, nhưng nó nắm bắt được cảm giác đó tốt hơn bất kỳ kỹ thuật nào trước đây.
Điều đó không có nghĩa các kỹ thuật nghệ thuật AI cũ hơn không liên quan hoặc không thú vị. Trên thực tế, The Big Sleep bị ảnh hưởng bởi một trong những kỹ thuật nghệ thuật mạng nơ-ron nhân tạo phổ biến nhất: DeepDream.
DeepDream là một kỹ thuật nghệ thuật AI cực kỳ phổ biến từ khoảng năm 2015. Kỹ thuật này lấy một hình ảnh và sửa đổi nó để hình ảnh đó kích hoạt tối đa các trong mạng nơ-ron nhân tạo theo cách phân loại hình ảnh. Kết quả hình ảnh thường rất ảo giác và rối mắt.

Một hình ảnh được tạo bởi DeepDream
Mặc dù về mặt thẩm mỹ DeepDream khá khác với The Big Sleep, nhưng cả hai kỹ thuật này đều nhằm mục đích trích xuất nghệ thuật từ các mạng nơ-ron nhân tạo để tạo ra nghệ thuật. Họ đi sâu vào bên trong mạng nơ-ron nhân tạo và lấy ra những hình ảnh đẹp. Những kỹ thuật nghệ thuật này giống như các công cụ học khả năng diễn giải vô tình tạo ra nghệ thuật trên đường đi.
Vì vậy, theo một cách nào đó, The Big Sleep giống như một phần tiếp theo của DeepDream. Trong trường hợp này, phần tiếp theo được cho là hay hơn phần gốc. Bất cứ điều gì bạn có thể diễn đạt thành lời sẽ được hiển thị thông qua ống kính giống như giấc mơ của người ngoài hành tinh. Và đó là cách làm nghệ thuật đầy mê hoặc.
VQ-GAN: Siêu năng lực phái sinh mới
Ngày 17/12/2020, các nhà nghiên cứu từ Đại học Heidelberg đăng bài báo “Chuyển đổi các máy biến áp để tổng hợp hình ảnh độ phân giải cao” trên Arxiv. Họ đã trình bày một kiến trúc GAN mới được gọi là VQ-GAN tạo ra một mô hình phái sinh đặc biệt mạnh mẽ.
Đầu tháng 4/2021, tài khoản @advadnoun và @RiversHaveWings trên Twitter bắt đầu thực hiện một số thử nghiệm kết hợp VQ-GAN và CLIP để tạo hình ảnh từ văn bản. Ở cấp độ cao, phương pháp họ sử dụng hầu hết giống với The Big Sleep. Sự khác biệt chính thực sự chỉ là thay vì sử dụng Big-GAN như mô hình chung, hệ thống này đã sử dụng VQ-GAN. Kết quả là một sự thay đổi lớn về phong cách.

“Nhảy dưới ánh trăng” từ VQ-GAN+CLIP (Nguồn: @advadnoun on Twitter)
Kết quả đầu ra từ VQ-GAN và CLIP có xu hướng giống một tác phẩm điêu khác hơn The Big Sleep. Với những hình ảnh quá trừu tượng để trở thành hiện thực, chúng vẫn như thể được tạo ra bằng tay.
Chỉ cần hoán đổi mô hình chung từ Big-GAN sang VQ-GAN, bạn đã có được một nghệ sĩ với phong cách mới và quan điểm độc đáo riêng với cách nhìn thế giới qua con mắt CLIP. Điều này làm nổi bật tính tổng quát của hệ thống dựa trên CLIP.
Các mô hình phát hành mới có thể sử dụng với CLIP mà không gặp quá nhiều khó khăn. Chúng ta có thể tạo ra tác phẩm nghệ thuật với phong cách và hình thức mới. Trên thực tế, điều này đã xảy ra ít nhất một lần: chưa đầy 8 giờ sau khi trọng số dVAE của DALL-E được phát hành công khai, @advadnoun đã đăng bài trên Twitter về tác phẩm nghệ thuật được thực hiện bằng dVAE + CLIP.
Niềm vui của việc lập trình Prompt: Thủ thuật công cụ không thực tế
Chuyển đổi mô hình tổng hợp có thể thay đổi đáng kể kiểu đầu ra của CLIP mà không cần quá nhiều nỗ lực, nhưng có một cách đơn giản hơn để thực hiện điều này. Bạn chỉ cần thêm một số từ khóa cụ thể vào mô tả cho biết điều gì đó về phong cách của hình ảnh mong muốn của bạn. CLIP sẽ cố gắng hết sức để “hiểu” và tạo ra đầu ra phù hợp.
Ví dụ: bạn có thể thêm “theo phong cách trò chơi điện tử Minecraft” hoặc “theo phong cách phim hoạt hình” hoặc thậm chí “theo phong cách DeepDream” vào mô tả của bạn. CLIP trả về nội dung gần giống với phong cách được mô tả.
CLIP đã học được các cách biểu diễn đủ tổng quát để tạo ra kết quả mong muốn từ mô hình. Tất cả những gì chúng ta cần làm là yêu cầu nó trong mô tả. Tuy nhiên, việc tìm ra những từ phù hợp để có được kết quả đầu ra tốt nhất sẽ là một thách thức lớn.

“Một túp lều nhỏ trong trận bão tuyết gần đỉnh núi có một đèn bật sáng vào lúc hoàng hôn đang thịnh hành trên xu hướng nghệ thuật” – yêu cầu từ VQ-GAN + CLIP cho (Nguồn: @ak92501 trên Twitter)
Hình ảnh này trông không giống như nghệ thuật VQ-GAN + CLIP trong phần trước. Kết quả đầu ra vẫn có chất lượng siêu thực nhất định. Tuy cấu trúc hình ảnh có thể bị phá vỡ ở một vài điểm, nhưng nhìn chung, chúng trông vẫn giống như những bức ảnh đã được chỉnh sửa hoặc những cảnh từ một trò chơi điện tử. Trong trường hợp này, từ khóa “thịnh hành trên xu hướng nghệ thuật” đóng vai trò quan trọng trong việc xác định phong cách độc đáo của kết quả đầu ra.
Hệ thống nghệ thuật dựa trên CLIP hoạt động và tạo ra khối lượng tác phẩm nghệ thuật lớn. Nhưng trong thực tế, đây mới chỉ là sự bắt đầu của các tác phẩm nghệ thuật AI. Trong tương lai, có rất nhiều điều cần cải thiện, xây dựng và khám phá mới.
Nguồn: https://ml.berkeley.edu/












